-
CPU와 GPU 비교와 GPGPU 프로그래밍의 이해Apple🍎/Metal 2025. 3. 27. 21:33
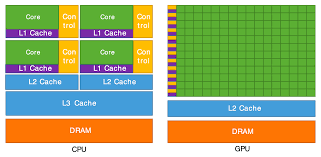
CPU와 GPU의 기본 구조와 연산 방식
CPU (중앙처리장치)의 구조와 작동 원리
CPU는 컴퓨터의 '두뇌'로 불리며, 몇 개의 강력한 코어로 구성되어 있습니다. 전통적인 CPU는 4~16개 정도의 코어를 가지고 있으며, 각 코어는 복잡한 명령어를 처리할 수 있는 고성능 연산 유닛입니다.
CPU의 주요 특징
- 직렬 처리(Serial Processing): 하나의 코어는 기본적으로 한 번에 하나의 작업을 순차적으로 처리합니다.
- 복잡한 제어 로직: 분기 예측(Branch Prediction), 명령어 파이프라이닝(Instruction Pipelining), 비순차적 실행(Out-of-Order Execution) 등 복잡한 제어 로직을 갖추고 있습니다.
- 대용량 캐시 메모리: L1, L2, L3 등 여러 계층의 캐시를 통해 메모리 접근 지연을 최소화합니다.
- 다양한 명령어 집합: 다양한 종류의 연산을 처리할 수 있는 범용 명령어를 지원합니다.
CPU가 명령어를 처리하는 과정을 간단히 살펴보면
- 명령어 인출(Fetch): 메모리에서 명령어를 가져옵니다.
- 해독(Decode): 명령어가 무엇을 의미하는지 해석합니다.
- 실행(Execute): 실제 연산을 수행합니다.
- 메모리 접근(Memory Access): 필요시 메모리에 접근합니다.
- 결과 저장(Write Back): 연산 결과를 레지스터나 메모리에 저장합니다.
GPU (그래픽처리장치)의 구조와 작동 원리
GPU는 원래 그래픽 렌더링을 위해 설계되었으나, 그 병렬 처리 능력이 일반 연산에도 유용하다는 것이 발견되었습니다. 현대 GPU는 수천 개의 작은 코어로 구성되어 있습니다.
GPU의 주요 특징
- 대규모 병렬 처리(Massive Parallel Processing): 수천 개의 작은 코어가 동시에 작업을 처리합니다.
- SIMD(Single Instruction, Multiple Data) 아키텍처: 동일한 명령어를 여러 데이터에 동시에 적용합니다.
- 고대역폭 메모리: 대용량의 데이터를 빠르게 처리하기 위한 고속 메모리 시스템을 갖추고 있습니다.
- 전문화된 연산 유닛: 부동소수점 연산, 행렬 연산 등에 최적화된 특수 유닛을 포함합니다.
GPU의 작동 방식은 다음과 같습니다.
- 많은 스레드(Thread)를 생성하여 각 데이터 요소에 할당합니다.
- 각 스레드는 동일한 프로그램(커널)을 실행하지만 다른 데이터에 적용합니다.
- 스레드는 워프(Warp) 또는 웨이브프론트(Wavefront)라는 그룹으로 관리되며, 그룹 내 모든 스레드는 동시에 동일한 명령어를 실행합니다.
- 메모리 접근이 효율적으로 이루어지도록 특수한 메모리 계층 구조를 활용합니다.
CPU와 GPU의 성능 비교
연산 방식의 근본적 차이
CPU와 GPU의 가장 큰 차이점은 작업 처리 방식에 있습니다.
- CPU: 소수의 복잡한 작업을 빠르게 처리하는 데 최적화되어 있습니다. 예를 들어, 웹 브라우징, 운영체제 관리, 사용자 입력 처리 등의 다양한 작업을 순차적으로 빠르게 처리합니다.
- GPU: 단순하지만 대량의 데이터를 병렬적으로 처리하는 데 최적화되어 있습니다. 이미지 렌더링, 물리 시뮬레이션, 머신 러닝의 행렬 연산과 같이 동일한 연산을 많은 데이터에 적용하는 작업에 뛰어납니다.
이를 비유하자면, CPU는 몇 명의 전문가가 복잡한 문제를 순차적으로 해결하는 방식이라면, GPU는 많은 작업자가 단순한 작업을 동시에 처리하는 방식이라고 볼 수 있습니다.
성능 특성 비교
코어 수 적음(4~64개) 많음(수천 개) 클럭 속도 높음(3~5GHz) 상대적으로 낮음(1~2GHz) 캐시 크기 크다(수십 MB) 작다(수 MB) 명령어 복잡성 높음 낮음 분기 처리 효율적 비효율적 병렬 처리 제한적 매우 효율적 단일 스레드 성능 매우 높음 낮음 멀티스레드 성능 제한적 매우 높음 CPU와 GPU의 상호작용 시 고려사항
데이터 전송 병목 현상
CPU와 GPU 간 데이터 전송은 주로 PCIe(PCI Express) 버스를 통해 이루어지며, 이는 종종 성능 병목의 원인이 됩니다.
- 제한된 대역폭: PCIe 5.0의 경우에도 GPU 내부 메모리 대역폭에 비해 훨씬 낮습니다.
- 전송 지연: 데이터 전송 시작부터 완료까지 상당한 지연 시간이 발생합니다.
- 해결 전략: 불필요한 데이터 전송을 최소화하고, 가능한 한 GPU 메모리에서 연산을 완료한 후 결과만 CPU로 전송하는 것이 좋습니다.
메모리 관리
CPU와 GPU는 각각 별도의 메모리 공간을 가지고 있습니다.
- 메모리 일관성: CPU와 GPU 간 데이터 일관성을 유지하는 것이 중요합니다.
- 메모리 할당 최적화: GPU 메모리 할당 및 해제는 CPU보다 비용이 크므로, 효율적인 메모리 재사용 전략이 필요합니다.
- 통합 메모리: 최신 아키텍처에서는 통합 메모리 접근(Unified Memory Access)을 제공하여 프로그래머가 명시적인 메모리 복사 없이 CPU와 GPU 간에 데이터를 공유할 수 있도록 합니다.
작업 분배 전략
효율적인 CPU-GPU 협업을 위해서는 적절한 작업 분배가 필요합니다.
- 작업 특성에 따른 할당: 직렬 처리가 필요한 복잡한 작업은 CPU에, 병렬화 가능한 데이터 집약적 작업은 GPU에 할당합니다.
- 오버헤드 고려: 작은 작업을 GPU로 오프로딩하는 것은 전송 오버헤드로 인해 오히려 비효율적일 수 있습니다.
- 비동기 실행: CPU와 GPU가 동시에 다른 작업을 처리하도록 비동기 실행을 활용합니다.
동기화 문제
CPU와 GPU 간 작업 동기화는 중요한 고려사항입니다.
- 명시적 동기화: 결과가 필요한 시점에 명시적 동기화를 사용합니다.
- 비동기 커널 실행: GPU 작업이 진행되는 동안 CPU가 다른 작업을 수행할 수 있도록 합니다.
- 이벤트 기반 동기화: 세밀한 제어를 위해 이벤트 기반 동기화를 활용합니다.
GPGPU 프로그래밍
GPGPU란?
GPGPU(General-Purpose computing on Graphics Processing Units)는 그래픽 처리 이외의 일반적인 계산에 GPU를 활용하는 기술입니다. GPU의 병렬 처리 능력을 활용하여 과학적 계산, 데이터 분석, 인공지능, 암호화 등 다양한 분야에서 성능을 크게 향상시킬 수 있습니다.
주요 GPGPU 프로그래밍 모델
CUDA (Compute Unified Device Architecture)
NVIDIA에서 개발한 CUDA는 가장 널리 사용되는 GPGPU 프로그래밍 플랫폼입니다.
// CUDA 커널 예제 __global__ void vectorAdd(float *a, float *b, float *c, int n) { // 스레드 인덱스 계산 int i = blockDim.x * blockIdx.x + threadIdx.x; // 배열 범위 내에서만 연산 수행 if (i < n) { c[i] = a[i] + b[i]; } } // 호스트 코드에서 커널 호출 vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_a, d_b, d_c, n);CUDA의 주요 특징
- C/C++ 기반의 프로그래밍 모델
- 스레드 계층 구조(그리드, 블록, 스레드)
- 다양한 메모리 유형(전역, 공유, 로컬, 상수 메모리)
- 풍부한 개발 도구 및 라이브러리
OpenCL (Open Computing Language)
Khronos Group에서 개발한 OpenCL은 다양한 하드웨어에서 작동하는 개방형 표준입니다.
// OpenCL 커널 예제 __kernel void vectorAdd(__global const float *a, __global const float *b, __global float *c, int n) { // 전역 작업 항목의 ID 가져오기 int i = get_global_id(0); // 배열 범위 내에서만 연산 수행 if (i < n) { c[i] = a[i] + b[i]; } }OpenCL의 주요 특징
- 다양한 하드웨어(CPU, GPU, FPGA 등) 지원
- 플랫폼 독립적 프로그래밍 모델
- 호스트-디바이스 구조
- 작업 및 데이터 병렬성 지원
기타 GPGPU 프로그래밍 접근법
- DirectCompute: Microsoft의 DirectX의 일부로, Windows 환경에서 GPU 컴퓨팅을 지원합니다.
- Vulkan Compute: 그래픽 API인 Vulkan의 컴퓨팅 기능으로, 저수준 제어를 제공합니다.
- 고수준 라이브러리: TensorFlow, PyTorch, NVIDIA cuDNN과 같은 고수준 라이브러리는 내부적으로 GPU를 활용하여 딥러닝 작업을 가속화합니다.
'Apple🍎 > Metal' 카테고리의 다른 글
[Particle Simulator] cpu 연산 - gpu 랜더링 방법 (0) 2025.03.30 Metal 렌더링 파이프라인 (0) 2025.03.29 cellular automata: 간단한 모래 시뮬레이터 만들기 (0) 2025.03.24 cellular automata(세포 자동자)는 뭘까? (0) 2025.03.23 Metal 둘러보기 (0) 2025.03.21