-
CS50 - SearchAI🤖/CS50 2024. 3. 3. 15:58
찾다.
인간은 살아가면서 다양한 문제 상황을 마주하고 이를 해결하기 위한 방법들을 ‘찾는’ 과정들로 삶은 채워진다.
게임속 미로에서 출구를 ‘찾을’ 수도 있고 현실 세계에서 목적지까지 가는 길을 ‘찾을’ 수도 있다.
Search ‘찾다’ 라는 행위를 분석해보자.
첫번째로 일단은 어떤 행동을 하고자 하는 주체가 존재해야한다.
게임속에서는 게임 캐릭터가 현실에서는 사람이 될것이다.두번째 주체는 어떠한 목적을 가지고 있어야한다.
게임속에서는 미로를 통과하자, 현실에서는 목적지에 도착하자 라는 목적이 있을 것이다.세번째 주체를 둘러싸고 있는 환경은 목적 달성을 방해하는 장애요소가 된다.
게임속에서는 이리저리 가로막고 있는 벽들이, 현실에서는 수많은 도로와 교통신호등이 될 것이다.네번째 주체는 환경 속에서 어떠한 상태에 놓여 있다.
게임속에서는 캐릭터가 미로의 입구나 미로 중간 어딘가에 놓여 있을 수 있으며, 현실에서는 집 앞 또는 목적지 앞 사거리에 놓여 있을 수 있다.다섯번째 주체는 놓여 있는 현재 상태를 기반으로 하여 행동을 취한다. -> 행동은 다음 상태를 결정한다.
게임속에서는 옆으로 간다던가 위쪽으로 갈수 있으며, 현실에서는 직진, 우회전 등이 가능하다.주체가 놓여 있는 상태를 기반으로 다음에 할 행동을 결정하고 이 행동은 또 다른 상태를 만들어 새로운 행동을 유발한다.
이러한 과정이 반복되며 모인 일련의 행동들로 목적을 달성하게 되면 이를 문제에 대한 해결책을 ‘찾았다고 할 수 있다.’즉 찾는다는 것은 문제를 해결하기 위한 일련의 행동집합을 도출하는 행위라고 할 수 있다.
Search Problem
- 타일 퍼즐 : 무작위로 섞여 있는 타일을 움직여 숫자 순서대로 정렬 시키는 퍼즐

위와 같은 퍼즐을 컴퓨터가 풀도록 하기 위해서는 구체적인 행동 지침을 알려줘야 한다.
이러한 구체적 행동 지침을 알고리즘이라고 하며 퍼즐의 정답을 만드는 과정을 ‘찾아야’ 하므로 이를
Search 알고리즘이라고 한다.Search 알고리즘을 컴퓨터에게 이해시키기 위해서는 먼저 용어에 대한 정의가 선행되어야한다.
- Agent (개체) : 개체는 현재 자신이 놓여있는 환경을 인식하고 목적을 달성하기 위한 행동을 판단하는 주체이다. 예를 들어 퍼즐에서는 타일을 움직이는 컴퓨터가 프로그램
- State (상태) : Agent가 놓여 있는 환경의 구성(이어떻게 이루어져 있는지) . 예를 들어 퍼즐에서는 타일들이 다양한 순서로 배치되어있다.
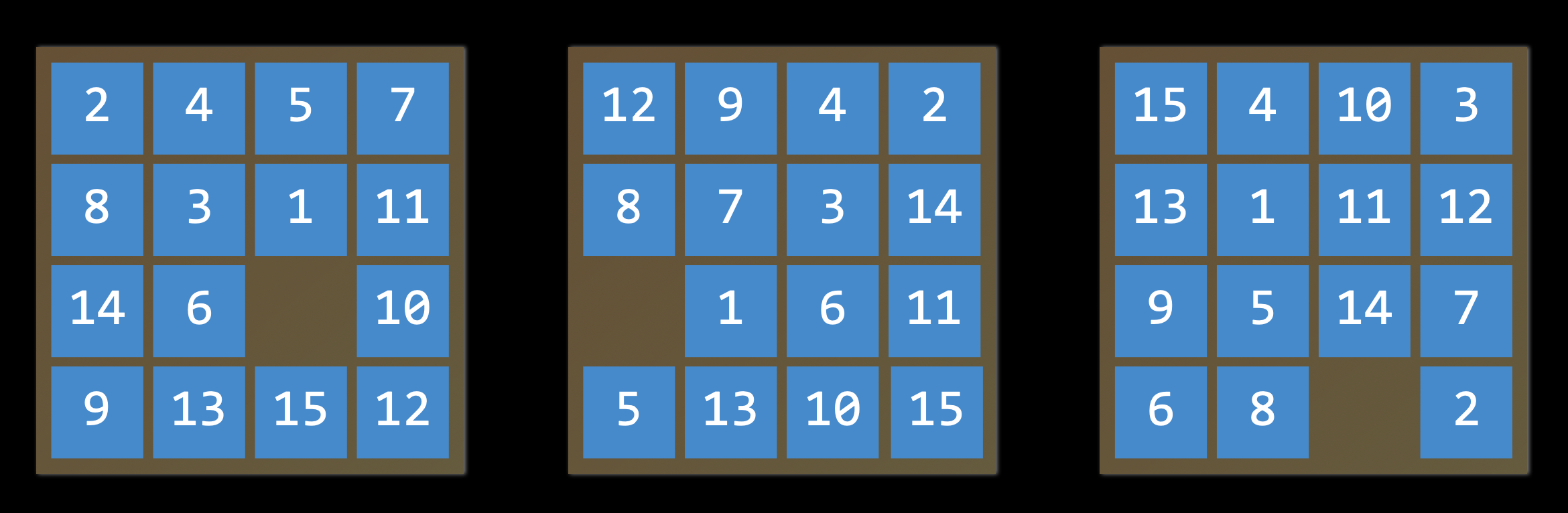
- Initial State (초기 상태) : State 중에서도 Agent가 환경에 처음 진입 했을 때의 State이다. -> Search 알고리즘이 시작하는 지점

- Actions(행위들) : 현재 State에서 할 수 있는 동작들 , 현재 상태 s가 입력으로 주어지면 현재 상태 s에서 할 수 있는 동작들의 집합이 출력으로 주어진다. 따라서 함수 Actions(s) 의 형태로 표현할 수 있다. 예를 들어 빈공간이 가운데 있으면 할 수 있는 행위들은 4가지(위,아래,왼쪽,오른쪽 타일 빈공간으로 옮기기) , 빈공간이 왼쪽 모서리에 있으면 할 수 있는 행위들은 2가지(위, 오른쪽 타일 빈공간으로 옮기기)

- Transition Model : 어떤 State에서 가능한 Actions 중 하나의 Action을 선택해서 취했을 때 어떤 상태로 변환하는지를 나타내는 모델로 상태 s와 선택한 행위 a를 입력으로 집어넣으면 다음 상태 s를 출력하는 함수이다. $$Result( s_current, a ) = s_next$$

- State Space : 개체가 초기 상태로부터 일련의 액션들을 통해 도달 가능한 모든 상태의 집합을 의미한다.
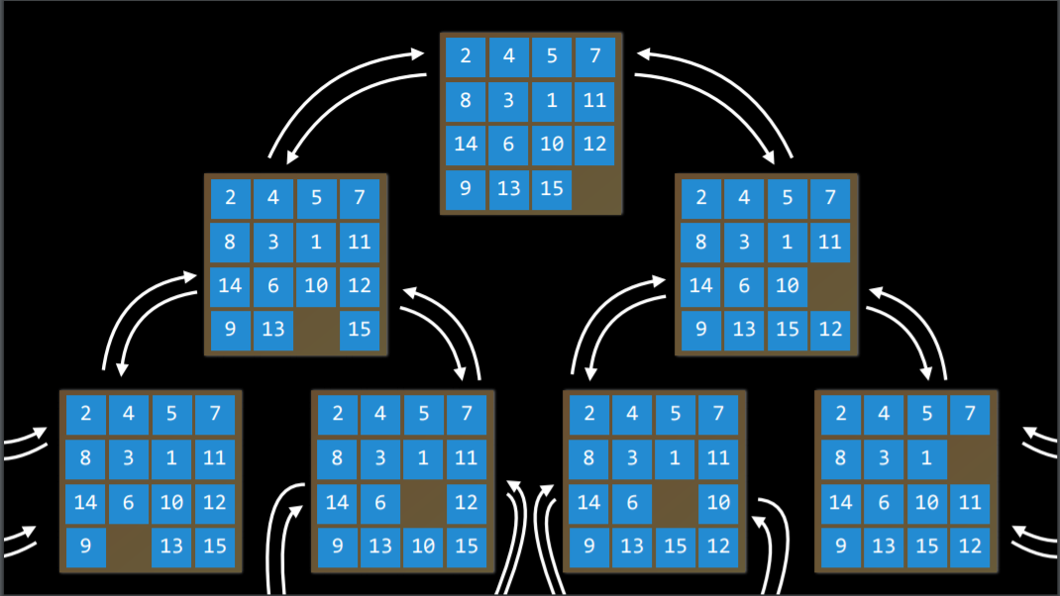
하나의 상태에서 액션을 통해 다른 상태로 변화하는 것(State Space) 을 시각적으로 나타내기 위해 다음과 같이 노드(점)과 화살표로 이루어진 그래프를 활용하기도 한다.
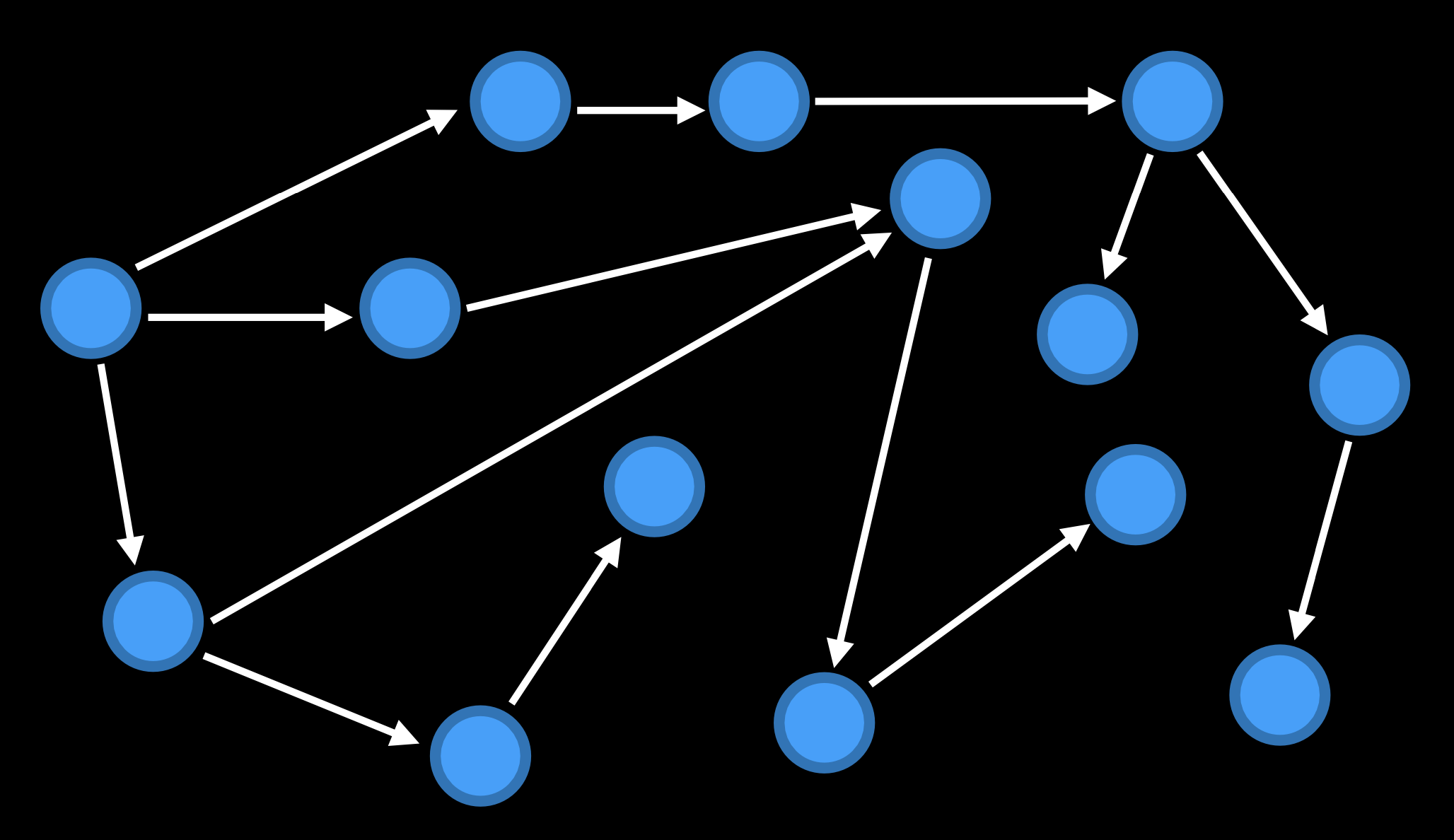
- Goal Test : 현재 상태가 목적 상태인지를 확인해가며 Search의 중단 여부를 판단한다. 현재 상태가 목적 상태와 같아진 경우 Search 알고리즘을 종료한다.
- Path Cost : 초기 상태에서 목적 상태까지 도달하는 과정은 여러가지가 될 수 있다. 그 중 가장 효율적인 방법을 찾는 것이 중요하다. 따라서 모든 Action에 비용을 부과한뒤 목적 상태까지 도달하는 데 있어서 비용을 최소화하는 과정을 찾는다.

- Solution : 초기상태로부터 목적 상태까지 도달가능하게 만드는 일련의 Action들을 Solution 이라고 한다.
- Optimal Solution : Solution 중에서도 path cost(비용)을 최소화하면서 목적 상태에 도달 가능하게 만드는 일련의 Action들을 Optimal(최적) Solution이라고 한다.
Node
Node는 Search Problem과 같이 그래프 형태로 나타 나는 문제들을 잘 표현할 수 있는 데이터 구조이다.
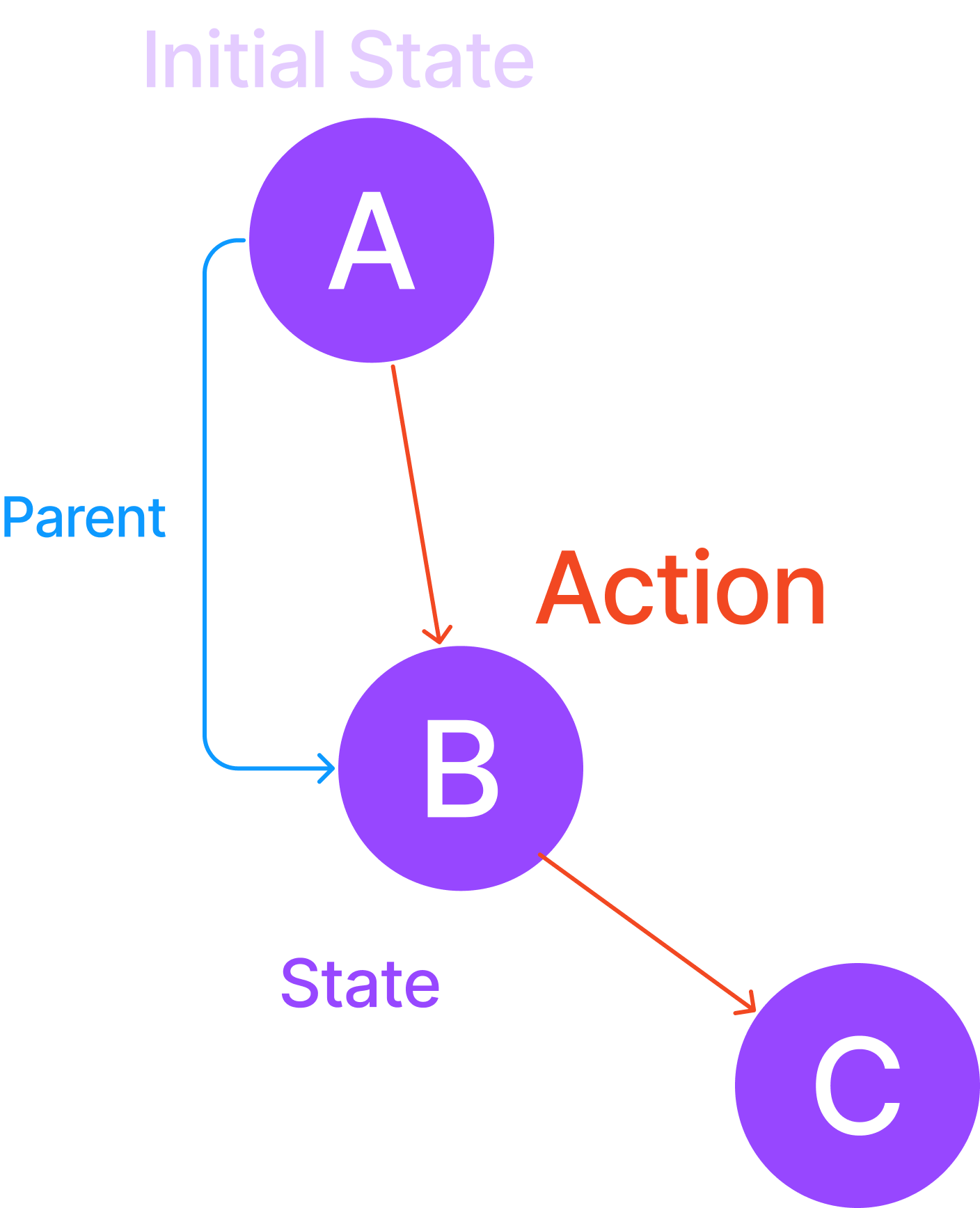
- State : 각 노드는 각 상태를 나타낸다. ex ) 노드들은 각각 A, B, C 라는 상태를 보여준다.
- Initial State : 출발 노드를 의미한다.
- Parent : 현재 노드의 이전 노드를 나타낸다. ex ) 노드 A는 노드 B의 이전 상태로 노드 A는 노드 B의 부모이다.
- Action : 노드간의 이동을 나타낸다.
- Path Cost : 출발 노드로부터 현재 노드까지 도달하는데 필요한 액션의 수를 나타낸다. ex) 노드 C의 Path Cost는 2
Node는 Search Problem이 가지고 있는 정보들을 담는 단순한 데이터 구조일 뿐이다. 노드를 통해 구조화한 문제를 해결하기 위해 도입한 개념 Frontier다.
Frontier
Frontier는 현재 노드에서 Action(이동)을 통해 도달할 수 있는 노드들을 기록해 놓는 곳이다.
일종의 정찰(아직 직접 가보지는 않은 상태)된 노드들이라고 할 수 있다.
Frontier에 있는 노드들 중에서 다음 노드를 선택하는 방법을 달리함으로써 Search 알고리즘이 달라진다.Frontier에는 첫번째 노드(초기 상태)가 놓인 상태로 시작하며 다음 조건에 따라 탐색을 반복한다.
- Frontier에 아무 노드도 존재하지 않게 되면 Solution이 존재하지 않는다.
- Frontier에서 노드를 꺼내면서 해당 노드로 이동한다.
- 새로 이동한 노드가 목표 노드와 동일할시 이를 반환하고 Search를 종료한다.
- 새로운 노드로 이동했을 때, 해당 노드에서 도달 가능한 노드들을 Frontier에 추가한다.
Search Problem이 다음과 같이 주어졌을 때 (노드A에서 시작해 노드 E를 찾아라)
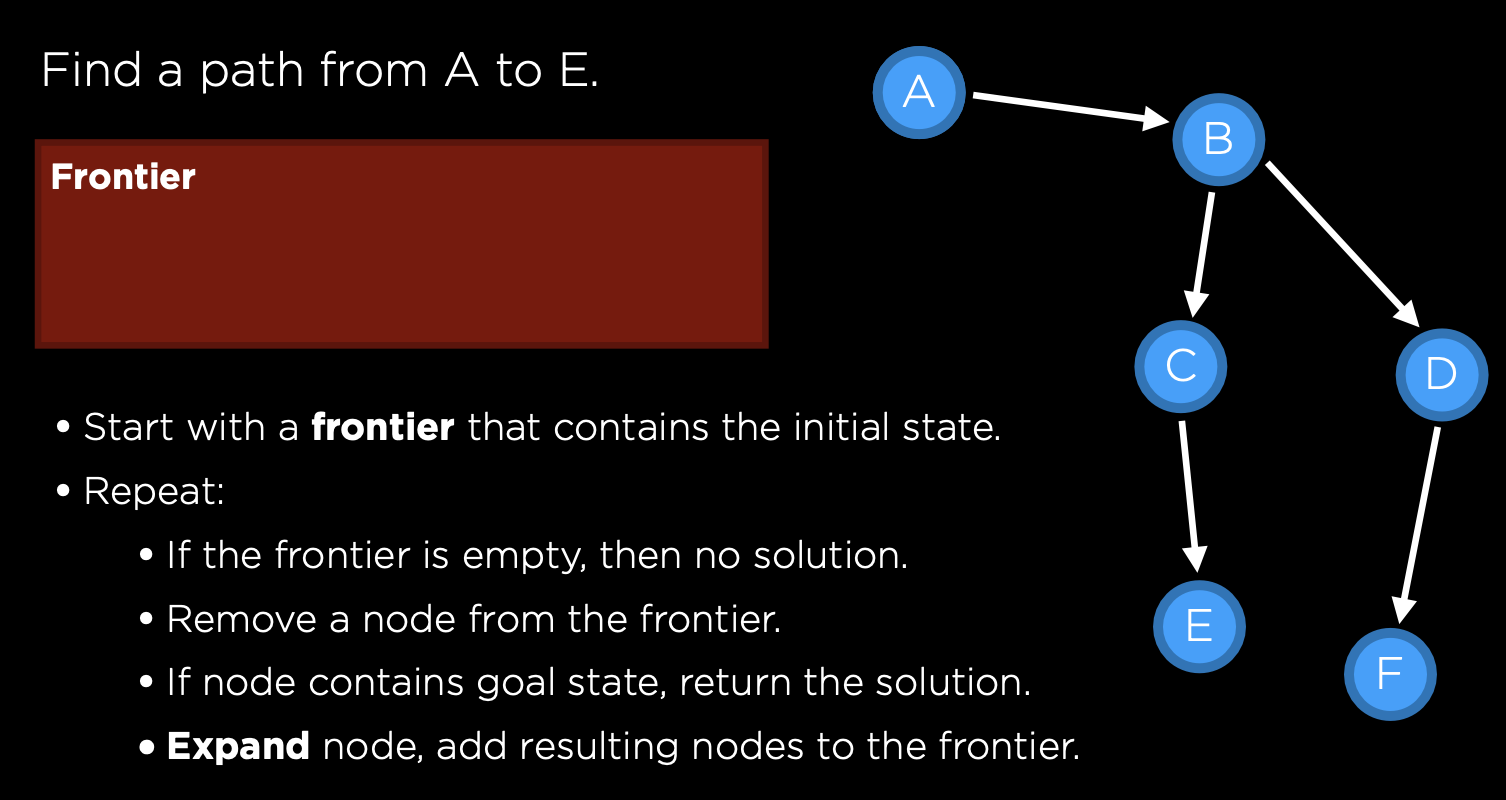
첫번째로 Frontier에 초기 상태인 노드 A를 올려둔 상태에서 Search를 시작한다.


- Frontier에서 노드 A를 꺼내면서 노드 A로 이동한다.
- 이동한 노드 A에서 도달 가능한 노드 B를 Fontier에 추가한다.
- Frontier에서 노드 B를 꺼내면서 노드 B로 이동한다.
- 이동한 노드 B에서 도달 가능한 노드 C,D를 Frontier에 추가한다.
- Frontier에서 노드 C를 꺼내면서 노드 C로 이동한다.
- 이동한 노드 C에서 도달가능한 노드 E를 Frontier에 추가한다.
- Frontier에서 노드 E를 꺼내면서 노드 E로 이동한다.
새로 이동한 노드 E가 목표노드와 동일하므로 이를 solution으로 반환하고 Search를 종료한다.

Explored Set
Search 알고리즘을 구성하는데 Frontier만으로도 충분해 보이지만 다음과 같은 경우를 한번 살펴보자.

A와 B사이와 같이 양방향 경로가 있는 경우, Frontier에 이미 도달한 노드 A와 B가 계속해서 서로를 새로 추가함으로써 순환하는 문제가 발생할 수 있다. 따라서 이러한 순환 문제를 방지하기 위해 위의 알고리즘을 조금 수정해보자.
Frontier에는 첫번째 노드(초기 상태)가 놓인 상태로 시작하며 이때 explored set은 비어있다. 다음 조건에 따라 탐색을 반복한다.
- Frontier가 비게되면 Solution이 존재하지 않는다.
- Frontier에서 노드를 꺼내면서 해당 노드로 이동한다.
- 새로 이동한 노드가 목표 노드와 동일할시 이를 반환하고 Search를 종료한다.
- 도달한 노드는 explored set(탐색된 노드)에 넣는다.
- 새로운 노드로 이동했을 때, 해당 노드에서 도달 가능한 노드들 중에서 explored set에 있는 노드를 제외한 노드들을 Frontier에 추가한다.
explored set은 이미 한번 도달한 노드를 기억하는 장치로 노드들이 서로를 참조하며 발생하는 순환문제를 해결할 수 있다.
Stack과 Queue
Frontier에 있는 노드들 중에서 다음으로 이동할 노드를 선택할 때 어떠한 기준을 따를지에 따라 Search 알고리즘이 달라진다.
- Frontier에 가장 최근에 들어온 노드를 먼저 탐색해본다. (Last In First Out)
- Frontier에 먼저 들어온 노드를 먼저 탐색해본다. (First In First Out)
앞서 수정한 알고리즘을 바탕으로 두 탐색 방법이 서로 어떻게 다른지 알아보도록 하자.
Last In First Out

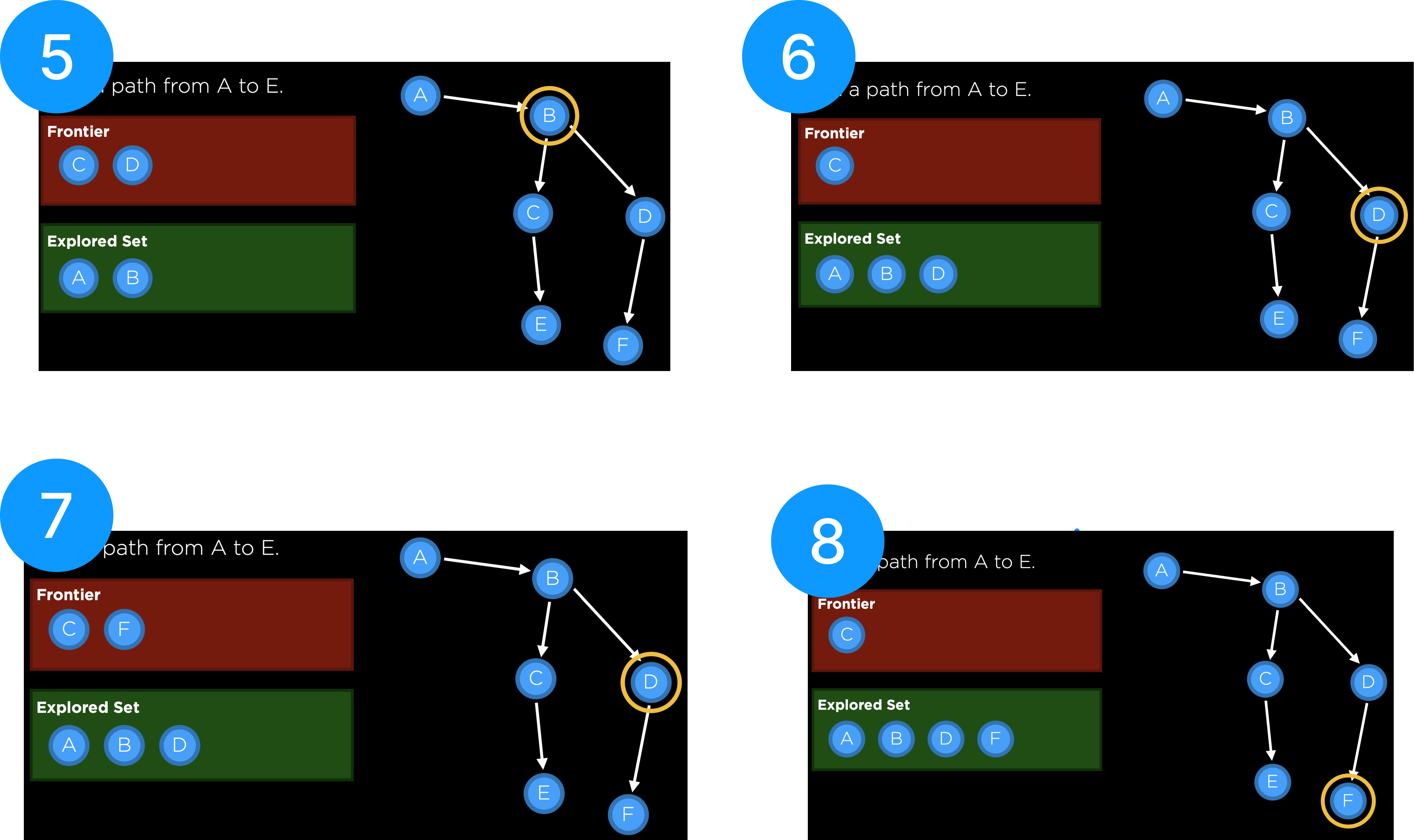

- Frontier에 초기 상태인 노드 A를 넣은 상태에 시작한다.
- Frontier에서 노드 A를 꺼내 Explored Set에 넣고 노드 A로 이동한다.
- 이동한 노드A에서 도달가능하며 Explored Set에 존재하지 않는 노드 B를 Frontier에 포함시킨다.
- Frontier에서 노드 B를 꺼내 Explored Set에 넣고 노드 B로 이동한다.
- 이동한 노드B에서 도달가능하며 Explored Set에 존재하지 않는 노드 C,D를 Frontier에 포함시킨다.
- Frontier에서 나중에 들어온 노드 D를 꺼내 Explored Set에 넣고 노드 D로 이동한다.
- 이동한 노드D에서 도달가능하며 Explored Set에 존재하지 않는 노드 F를 Frontier에 포함시킨다.
- Frontier에서 가장 나중에 들어온 노드 F를 꺼내 Explored Set에 넣고 노드 F로 이동한다.
- Frontier에서 C를 꺼내 Explored Set에 넣고 노드 C로 이동한다.
- 이동한 노드C에서 도달가능하며 Explored Set에 존재하진 않는 노드 E를 Frontier에 포함시킨다.
- Frontier에서 E를 꺼내 Explored Set에 넣고 노드 E로 이동한다. -> 이동한 노드가 목적 노드와 동일해졌으므로 Search를 종료한다.
Last In First Out 방식으로 진행된 Search 과정을 살펴보면 탐색중인 노드에서 경로가 여러개로 나누어지는 경우, 일단 하나의 경로를 선택하면 그 경로를 타고 끝까지 내려가 본뒤에 다시 분기점으로 돌아와 다음 경로를 탐색하였다. 이렇게 일단 한쪽 경로를 깊이 탐색하는 것을 깊이 방향을 먼저 탐색한다 하여 Depth-First Search라고 한다.
DFS 알고리즘의 경우 깊이 방향을 탐색하기 위해서 Frontier에 가장 마지막에 들어온 노드를 먼저 내보내는 방식인 Stack을 사용한다.
First In First Out
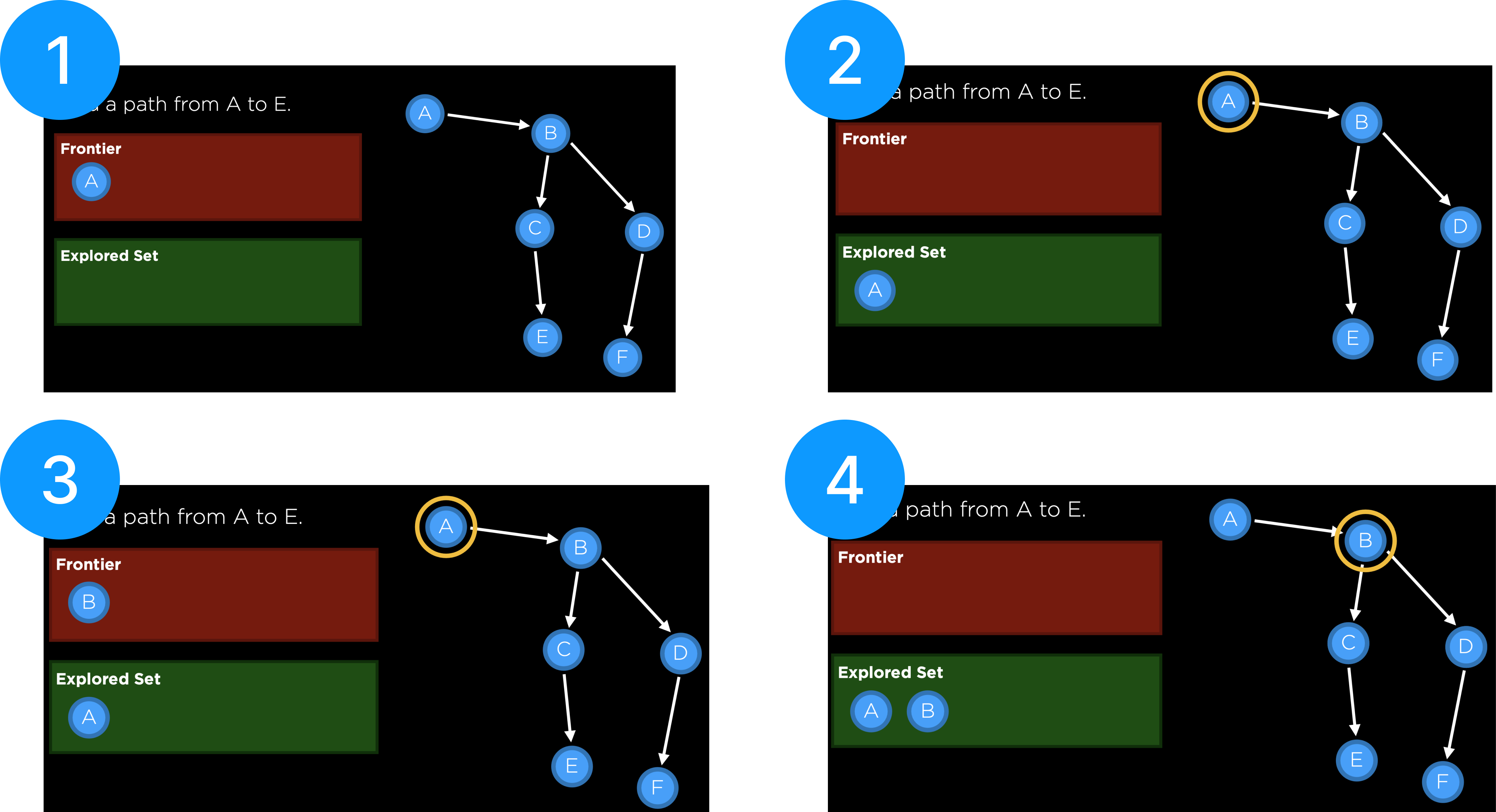

- Frontier에 초기 상태인 노드 A를 넣은 상태에 시작한다.
- Frontier에서 노드 A를 꺼내 Explored Set에 넣고 노드 A로 이동한다.
- 이동한 노드A에서 도달가능하며 Explored Set에 존재하지 않는 노드 B를 Frontier에 포함시킨다.
- Frontier에서 노드 B를 꺼내 Explored Set에 넣고 노드 B로 이동한다.
- 이동한 노드B에서 도달가능하며 Explored Set에 존재하지 않는 노드 C,D를 Frontier에 포함시킨다.
- Frontier에서 먼저 들어온 노드 C를 꺼내 Explored Set에 넣고 노드 C로 이동한다.(노드 C에서 도달가능하며 Explored Set에 존재하지 않는 노드 E를 Frontier에 포함시킨다.)
- Frontier에서 가장 먼저 들어온 노드 D를 꺼내 Explored Set에 넣고 노드 D로 이동한다. (노드 D에서 도달가능하며 Explroed Set에 존재하지 않는 노드 F를 Frontier에 포함시킨다.)
- Frontier에서 가장 먼저 들어온 노드 E를 꺼내 Explored Set에 넣고 노드 E로 이동한다. -> 이동한 노드가 목적 노드와 동일해졌으므로 Search를 종료한다.
First In First Out 방식으로 진행된 Search 과정을 살펴보면 탐색중인 노드에서 경로가 여러개로 나누어지는 경우, 하나의 경로를 들어갔더라도 다시 분기점으로 돌아와 다른 경로 또한 탐색한다. 이렇게 모든 경로를 넓게 탐색하는 것을 넓이 방향을 먼저 탐색한다 하여 Breadth-First Search라고 한다.
BFS 알고리즘의 경우 넓이 방향을 탐색하기 위해서 Frontier에 가장 먼저 들어온 노드를 먼저 내보내는 방식인 Heap을 사용한다.
정리
Search 알고리즘은 Frontier에 어떠한 자료 구조를 적용하느냐에 따라 노드를 선택하는 방식이 달라진다.
Stack ( Last In First Out) 방식을 선택한 경우 깊이 방향 탐색(DFS)을 하며
Queue ( First In First Out) 방식을 선택한 경우 넓이 방향 탐색(BFS)을 한다.미로에서 적용해보기
앞서 정리한 Search 알고리즘들을 미로에서 길찾기에 적용한 경우를 살펴보며 DFS와 BFS가 어떤 과정을 통해 출구를 찾아내는지 확인해 보자.
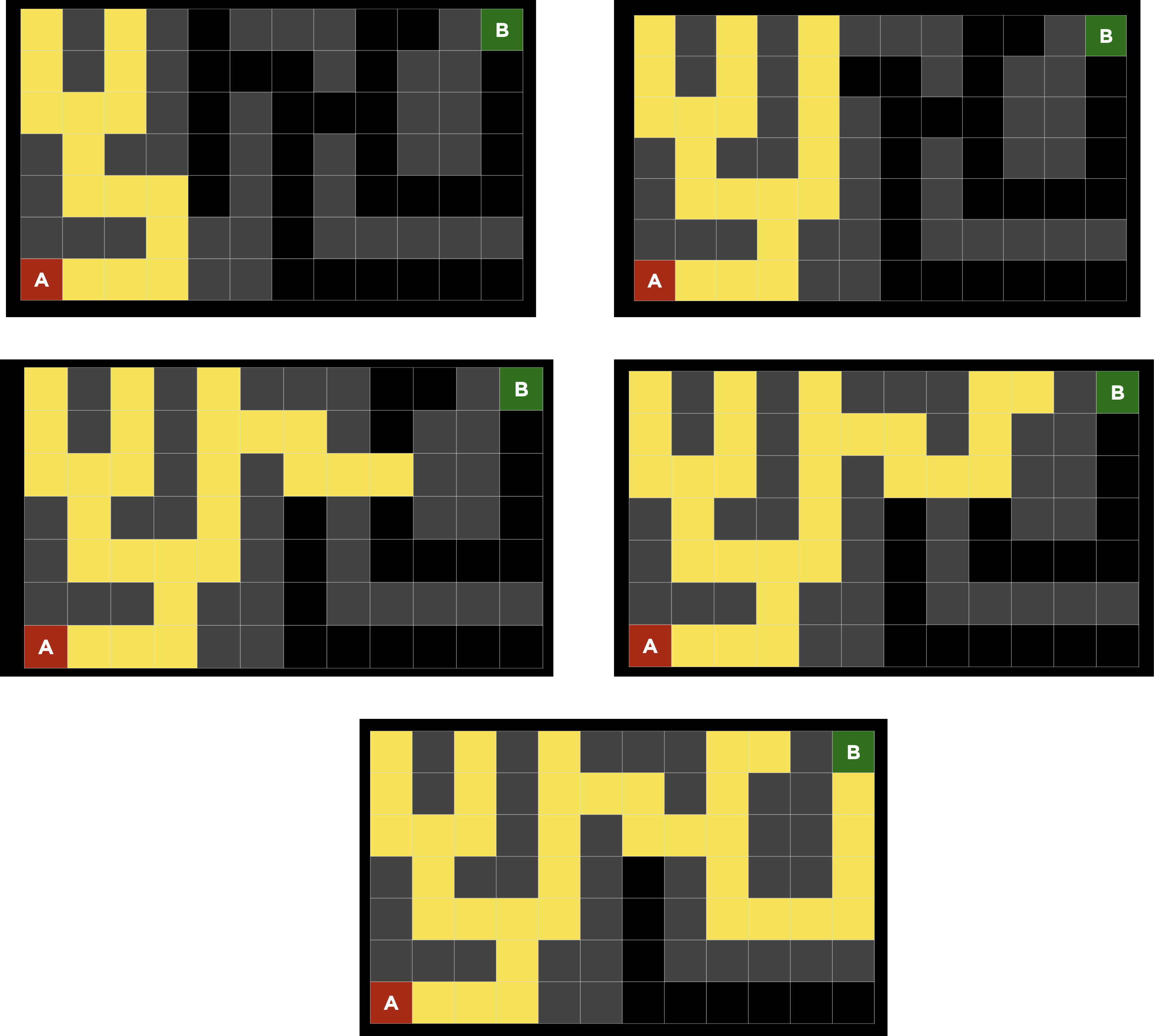
DFS
- 경로를 따라 내려가다가 분기점을 만난다.
- 분기점에서 하나의 경로를 선택하여 따라 내려간다.
- 막힌점을 만나면 가장 최근 분기점에서의 나머지 경로를 선택하여 내려간다.
- 목적지를 만나는 경우 Search를 종료한다.

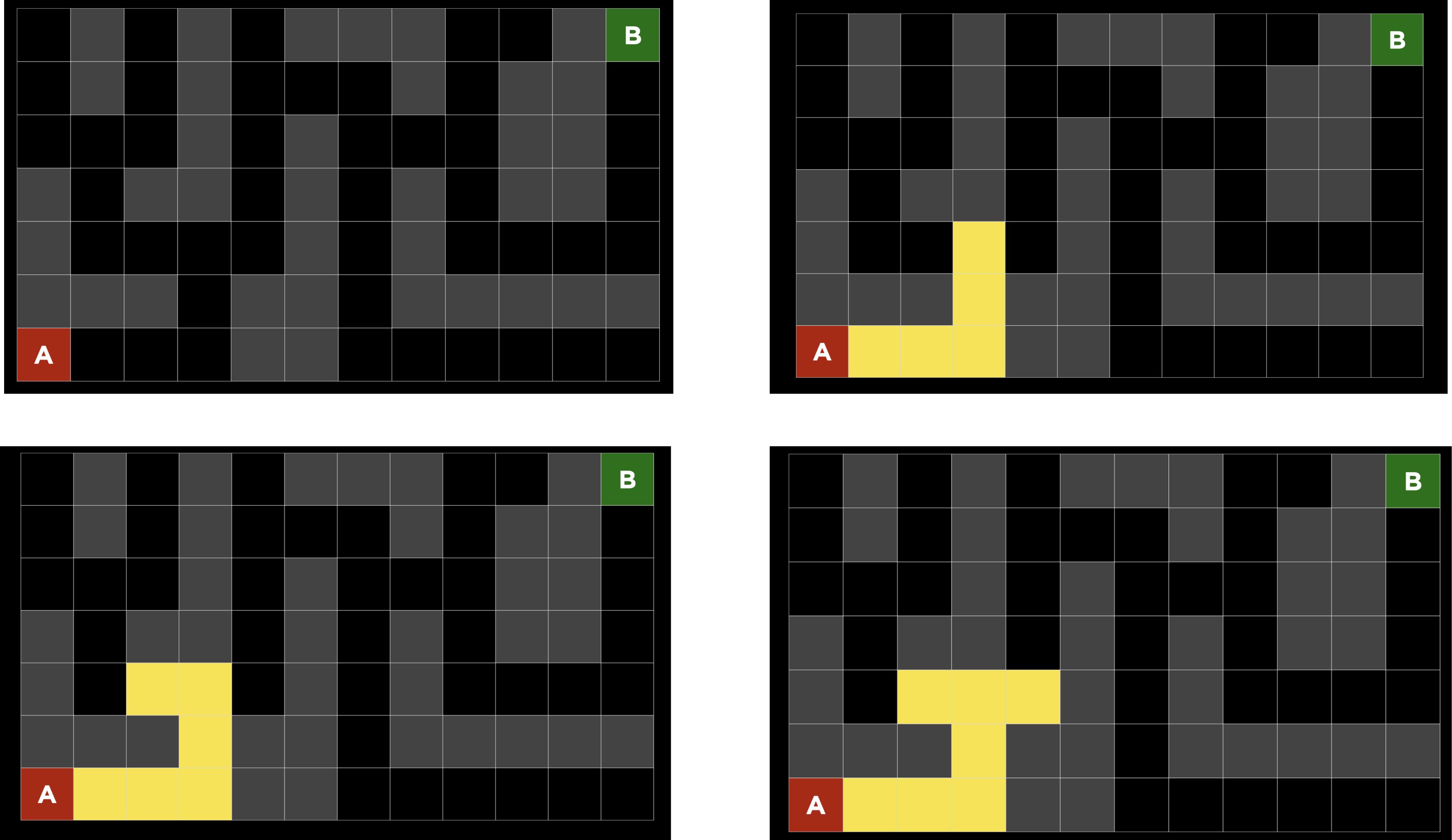
BFS
- 경로를 따라 내려가다 분기점을 만난다.
- 분기점에서 각 경로에 대해 한번씩 탐색을 진행한다.
- 새로운 분기점을 또 만나면 각 분기점에 대하여 차례대로 탬색 기회를 주고 각 분기점은 할당 받은 탐색기회를 해당 분기점의 각 경로에 대해 공평하게 나눈다.
- 목적지를 만나는 경우 Search를 종료한다.
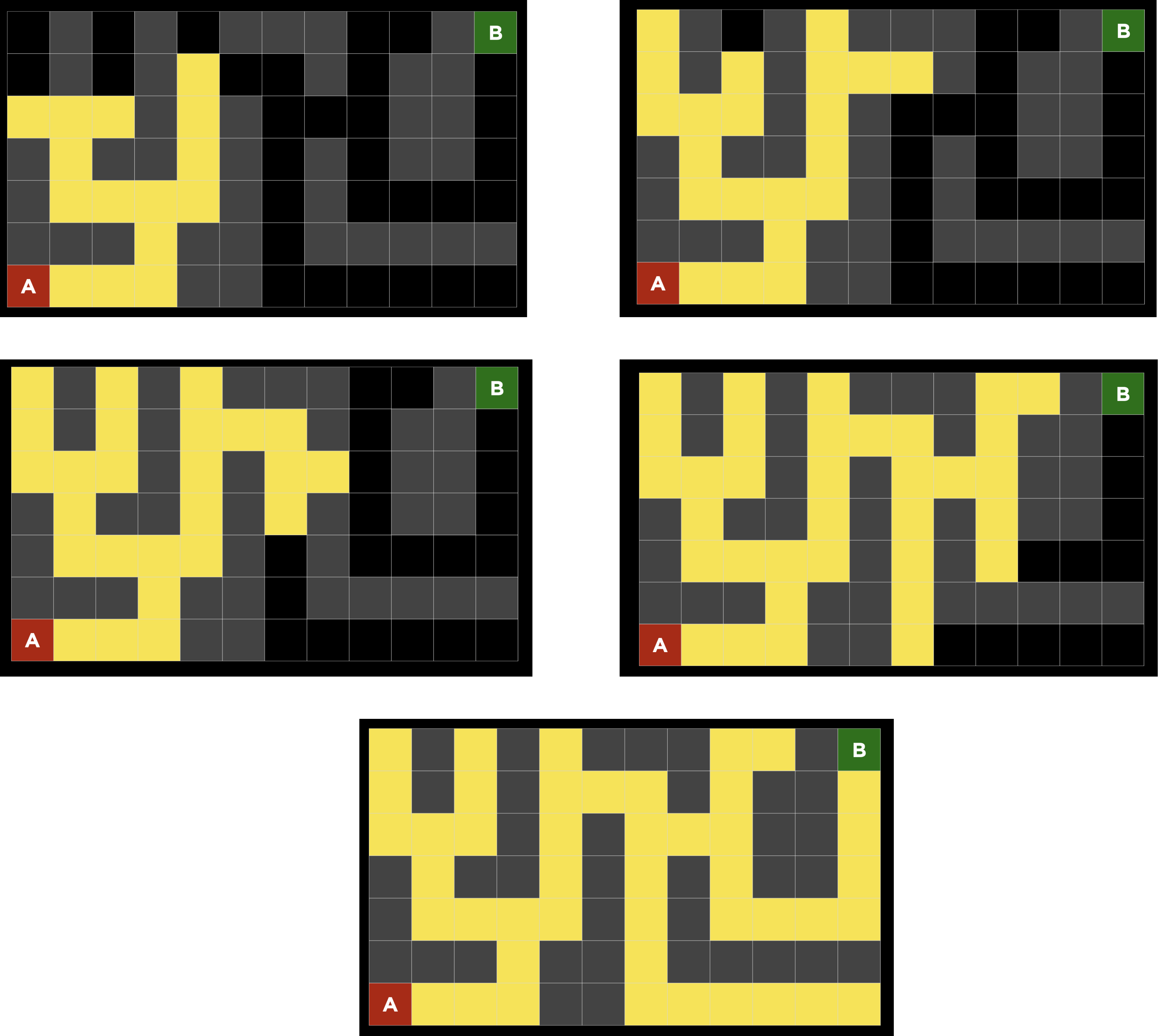
코드로 직접 실행해보기
import sys # Node 정의 class Node(): def __init__(self, state, parent, action): self.state = state #현재 위치 self.parent = parent #이전 위치 self.action = action # # Stack 방식의 Frontier -> DFS class StackFrontier(): # Frontier 초기화 def __init__(self): self.frontier = [] # Frontier에 Node 추가 def add(self, node): self.frontier.append(node) # 주어진 Node가 이미 Frontier에 포함되어 있는지 확인 def contains_state(self, state): return any(node.state == state for node in self.frontier) # Frontier가 비어있는지 확인 def empty(self): return len(self.frontier) == 0 # Frontier에서 node를 빼기 def remove(self): if self.empty(): raise Exception("empty frontier") # Frontier가 비게 되면 정답 없음 else: node = self.frontier[-1] # Stack은 Frontier에 가장 마지막에 들어온 node를 선택 self.frontier = self.frontier[:-1] # 마지막 node를 제외한 frontier로 변경 return node # 제거하는 node를 반환 # Queue 방식의 Frontier -> BFS # Frontier에서 node를 빼는 방식만 다르고 나머지 기능은 동일하므로 상속을 통해 해결 class QueueFrontier(StackFrontier): # Frontier에서 node를 빼는 방식이 달라짐 def remove(self): if self.empty(): raise Exception("empty frontier") # Frontier가 비게 되면 정답 없음 else: node = self.frontier[0] # Queue는 가장 먼저 들어온 node를 선택 self.frontier = self.frontier[1:] # 첫번째 node를 제외한 fronteir로 변경 return node class Maze(): # txt 파일을 읽어서 미로를 구성 def __init__(self, filename): # 파일을 읽어서 미로의 넓이와 높이를 세팅 with open(filename) as f: contents = f.read() # 주어진 미로가 유효한 미로인지 확인(출발지(A), 도착지(B)가 하나씩만 존재해야함 if contents.count("A") != 1: raise Exception("maze must have exactly one start point") if contents.count("B") != 1: raise Exception("maze must have exactly one goal") # 텍스트에서 높이와 넓이 뽑아내기 contents = contents.splitlines() # 줄별로 나누어서 리스트로 제공 self.height = len(contents) # 줄의 개수가 높이를 결정 self.width = max(len(line) for line in contents) # 가장 긴 줄이 넓이를 결정 # contents의 각 요소를 순회하면서 출발지,도착지,벽,길을 구분 self.walls = [] # 벽의 위치를 나타내는 2차원 배열 for i in range(self.height): row = [] for j in range(self.width): try: # 각 요소에 접근시 각 라인의 길이가 달라 IndexError가 발생가능하므로 Try 이용 if contents[i][j] == "A": self.start = (i,j) row.append(False) elif contents[i][j] == "B": self.goal = (i,j) row.append(False) elif contents[i][j] == " ": row.append(False) else: row.append(True) except IndexError: row.append(False) self.walls.append(row) self.solution = None # 미로의 상태를 시각적으로 출력 def print(self): solution = self.solution[1] if self.solution is not None else None print() # 공백줄 for i, row in enumerate(self.walls): for j, col in enumerate((row): if col: print("█", end="") elif (i,j) == self.start: print("A", end="") elif (i,j) == self.goal: print("B", end="") # end문은 문자를 줄바꿈없이 출력하기위해 사용 elif solution is not None and (i,j) in solution: print("*", end="") # solution 경로표시 else: print(" ", end="") print() print() # 주어진 state(위치)에 대해 이동가능한 방향 파악 def neighbors(self, state): row, col = state candidates = [ ("up", (row-1, col)), ("down", (row+1, col)), ("left", (row, col-1)), ("right", (row, col+1)) ] result = [] for action, (r,c) in candidates: # height와 width 범위에 들어오면서 벽이 아니어야 해당 방향으로 이동이 가능함 if 0 <= r < self.height and 0 <= c < self.width and not self.walls[r][c]: result.append((action, (r,c)) return result def solve(self): # 탐색 횟수 추적(cost) self.num_explored = 0 # 초기 노드와 Frontier 세팅 start = Node(state=self.start, parent=None, action=None) frontier = StackFrontier() # Stack 방식 Frontier 선택 frontier.add(start) # explored set 초기화 self.explored = set() # solution 찾을때까지 반복 while True: # frontier에 남은 Node가 없다면 solution 없음 if frontier.empty(): raise Exception("no solution") # frontier에서 꺼낼 Node 선택 node = frontier.remove() self.num_explored += 1 # 꺼낸 노드가 goal 과 같을 경우 -> solution 찾음 if node.state = self.goal: actions=[] # 동작 cells = [] # 좌표 while node.parent is not None: actions.append(node.action) cells.append(node.state) node = node.parent actions.reverse() cells.reverse() self.solution = (actions, cells) return # 꺼낸 노드 explored set에 추가 self.explored.add(node.state) # 꺼낸 노드에서 도달가능한 노드들 frontier에 넣기 for action, state in self.neighbors(node.state): # 대상이 되는 노드가 Fronteir에 이미 있는지 체크 # && 대상이 되는 노드가 Explored Set에 있는지 체크 if not frontier.contains_state(state) and state not in self.explored: child = Node(state=state, parent=node, action=action) frontier.add(child) # solution을 image로 processing 해서 현재 디렉토리에 maze.png로 저장 def output_image(self, filename, show_solution=True, show_explored=False): from PIL import Image, ImageDraw # 각 요소 크기 설정 cell_size = 50 cell_border = 2 # 빈 캔버스 만들기 img = Image.new( "RGBA". (self.width * cell_size, self.height * cell_size), "black" ) draw = ImageDraw.Draw(img) solution = self.solution[1] if self.soution is not None else None for i, row in enumerate(self.walls): for j, col in enumerate(row): # Walls if col: fill = (40, 40, 40) # Start elif (i, j) == self.start: fill = (255, 0, 0) # Goal elif (i, j) == self.goal: fill = (0, 171, 28) # Solution elif solution is not None and show_solution and (i, j) in solution: fill = (220, 235, 113) # Explored elif solution is not None and show_explored and (i, j) in self.explored: fill = (212, 97, 85) # Empty cell else: fill = (237, 240, 252) # Draw cell draw.rectangle( ([(j * cell_size + cell_border, i * cell_size + cell_border), ((j + 1) * cell_size - cell_border, (i + 1) * cell_size - cell_border)]), fill=fill ) img.save(filename) if len(sys.argv) != 2: sys.exit("Usage: python maze.py maze.txt") m = Maze(sys.argv[1]) print("Maze:") m.print() print("Solving...") m.solve() print("States Explored:", m.num_explored) print("Solution:") m.print() m.output_image("maze.png", show_explored=True)- StackFrontier 사용시 -> 총 194회

- QueueFrontier 사용시 -> 총 77회

앞서 주어진 미로에서는 StackFrontier를 사용한 DFS보다 QueueFrontier를 사용한 BFS 경우가 좀더 최적인 솔루션임을 알 수 있다.
하지만 항상 BFS가 DFS인 것보다 좋은 것도 아니며 그 반대의 경우도 마찬가지다.
아래 그림과 같은 미로에 BFS 알고리즘을 사용한다면 미로의 모든 노드를 거치고 나서야 goal에 도달할 수가 있다.

어떻게 하면 좀더 지능적으로 미로를 해결하여 최적의 솔루션을 찾을 수 있을까?
생각을 해보자. 인간이라면 어떻게 할까?

이른바 직관이라고 하는 것을 문재해결에 적용시켜보도록 하자.
첫번째 분기점에 이르렀을 때 DFS(깊이 우선 탐색)은 한쪽을 정해 해당 경로가 모두 소진 될때까지 파고 들어갈 것이고 BFS(넓이 우선 탐색)은 양 경로를 차례로 번갈아가면 넓혀 나갈 것이다.
만약 인간이라면? 미로를 봤을 때 오른쪽 경로를 택해야 도착지점(B)와 가까워지는 방향이라는 ‘느낌’을 받는다.
물론 단순 추정이기는 하지만 우리 모두 알다시피 꽤나 합리적이고 현실 상황에서도 잘 먹히는 방법이다.
이러한 인간의 느낌을 컴퓨터에게 어떻게 설명할 수 있을 까?
위와 같이 2차원의 미로에서는 각 지점에 x, y 좌표값을 부여 한뒤 분기점에서 한 경로를 선택 할 때 도착지점 좌표값과의 차이가 줄어드는(가까워지는) 경로를 선택하도록 하면 된다.Uninformed vs Informed Search 알고리즘
Uninformed 알고리즘
DFS나 BFS와 같이 현재 상태에서 가능한 액션중 하나를 선택하면 또 다른 상태에 도달하고 이를 반복하면서 목표지점에 다가가는 방식으로 직접 마주한 정보외에는 환경에 대한 부가적인 정보가 없는 상태에서의 Search 방법이다. 예를 들어 처음 들어간 숲속에서 길을 잃었을 때 여기저기 다 쑤시며 나가는 지점을 찾는 상황인 것이다.
Informed 알고리즘
위의 미로에서 인간이 목적지 위치를 시각으로 확인하고 이를 근거로 더 가까워지는 방향을 선택하는 것처럼
Uninformed 알고리즘과는 다르게 환경에 대한 부가적인 정보(목적지의 좌표값)가 있는 상태에서 최적의 솔루션을 찾는 Search 방법이다.Greedy best-first search
Informed 알고리즘의 일종으로 목적지의 좌표값을 아는 상태에서
목적지와 가까워질 거라고 생각하는 방향을 선택하는 방법이다.목적지의 좌표값을 안다고 해도 목적지에 가까워지는 최적의 방향을 알고 있는 상태는 아니다.
(알고 있다면 이미 솔루션이 나온 상태이다.)
그저 현재의 좌표값로부터 목적지까지 더 빨리 도달이 가능할거라는 추정이 드는 경로를 선택하는 것이다.
그리고 이 추정을 할 때 사용하는 함수를 휴리스틱 함수라고 한다.휴리스틱이란
불완전한 정보로 인해 이상적인 해결책을 얻기 어려운 상황에서 적당히 만족할만한 수준의 해답을 찾는 것이다. -> 알잘딱깔센하게휴리스틱 함수
위의 미로 예에서 C와 D 중에서 무엇을 선택하겠는가? 인간이라면 당연히 D를 선택하겠지만 컴퓨터에게 이 ‘당연히’를 이해시키기 위해서는 함수의 형태로 만들어 줘야한다. C와 D가 입력으로 주어졌을 때 출력이 D가 되게 하는 함수

여기서 휴리스틱 함수는 멘하튼 거리를 사용해 목적지의 좌표값과 차이가 더 적은 지점을 선택하도록 할 수 있다.
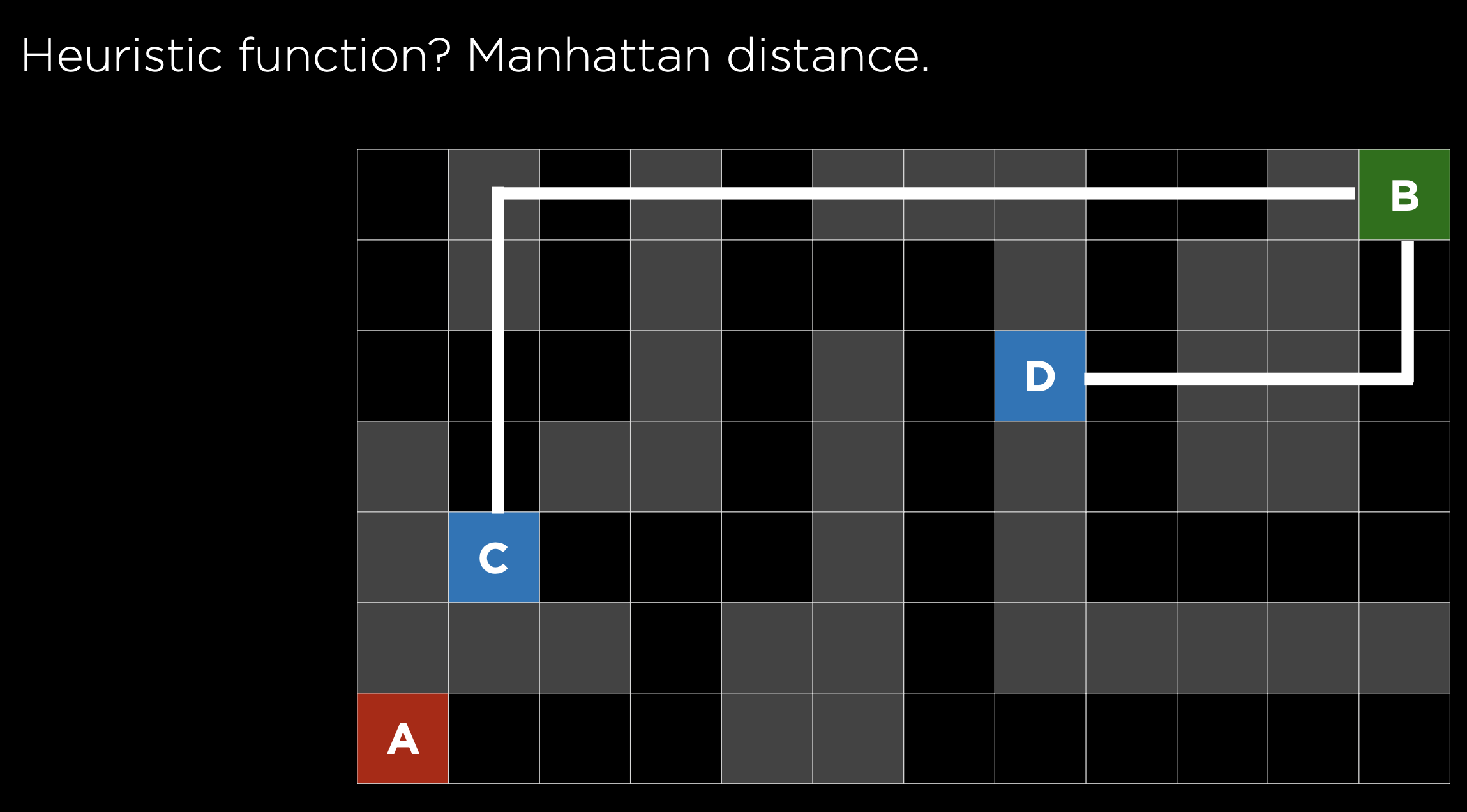
위에서 만든 휴리스틱 함수를 이용하면 미로에 있는 모든 위치에 목적지로부터의 맨하튼 거리 값을 부여할 수 있다. 따라서 출발지점부터 맨하튼 거리 값이 작아지는 노드를 선택하도록 하는 알고리즘을 짤 수 있다.

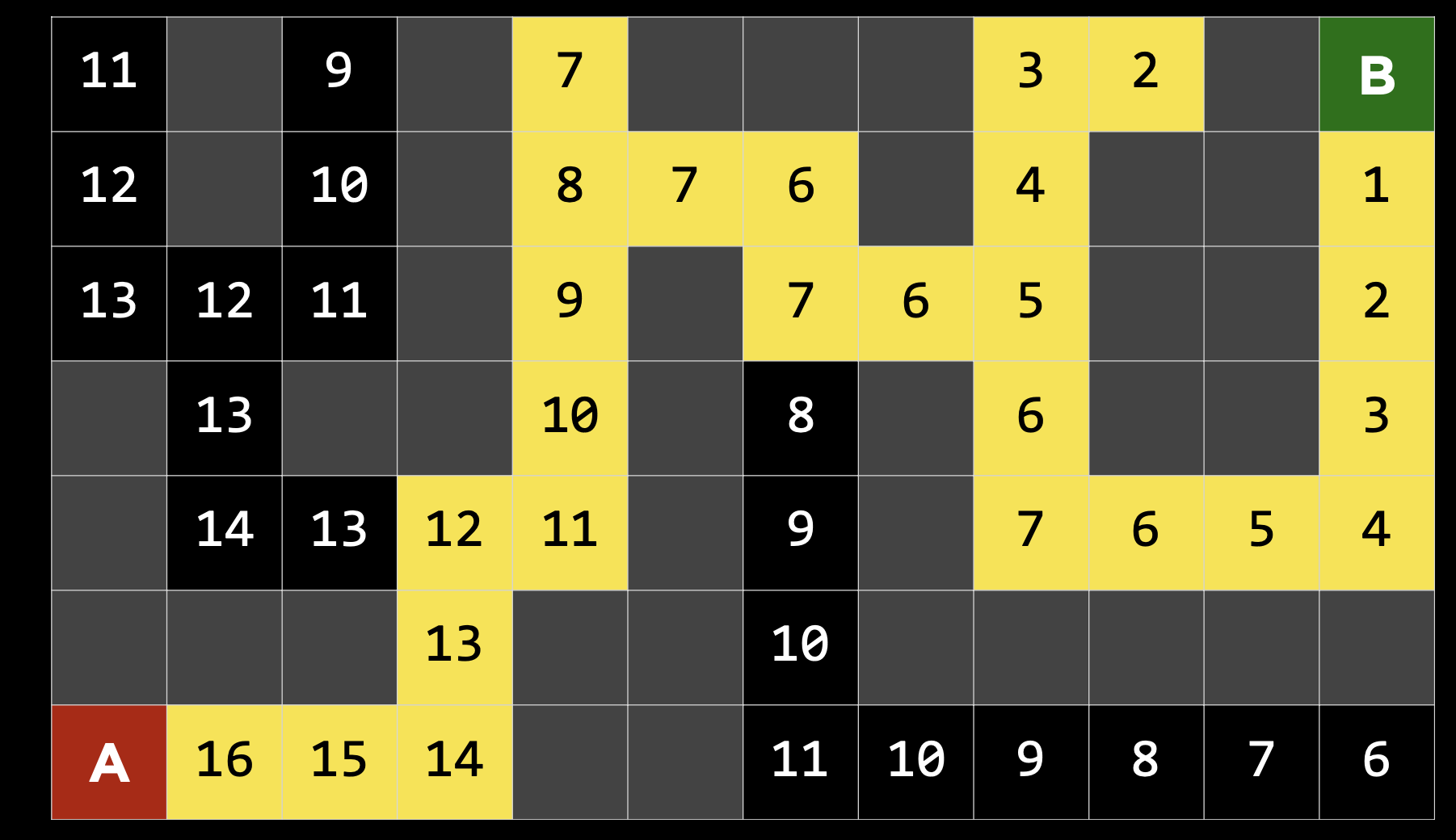
새로운 알고리즘을 통해 찾은 솔루션을 보면 꽤나 합리적인 경로처럼 보이지만 항상 주의를 해야한다.
휴리스틱 함수는 ‘추정’ 통한 방법이기 때문에 문제에 따라 적합도가 달라질 수 있다.예를 들어 아래와 같은 미로에서는 휴리스틱 함수상으로는 오른쪽 경로를 선택하는 것이 좋다고 추정 되지만 사실은 위쪽 경로의 비용이 더 적다.
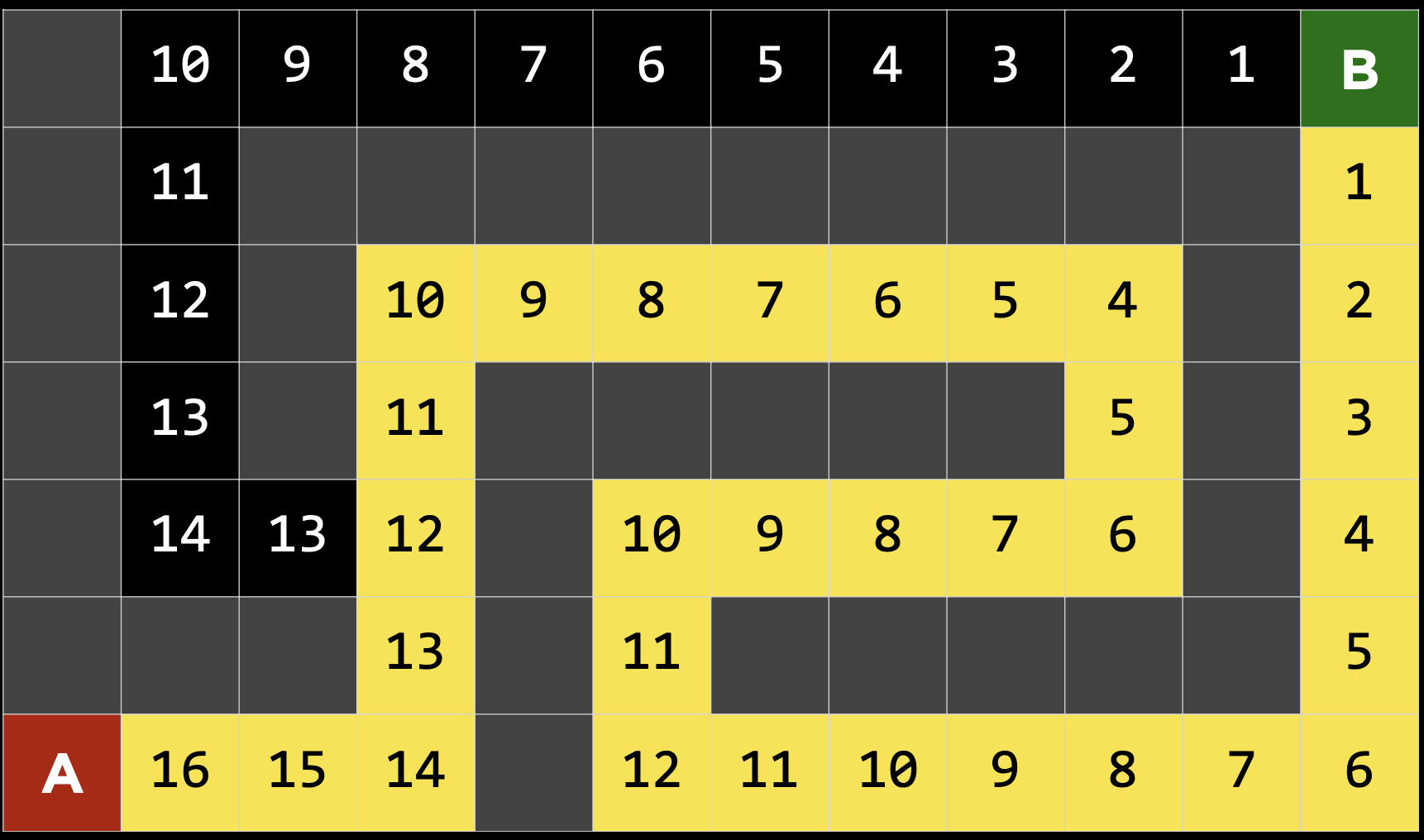
분명 오른쪽 경로가 맨하튼 거리값은 더 작았지만 중간에 돌아가는 부분이 있어 최종적으로는 더 많은 비용이 들었다. 이렇게 중간에 돌아가는 경우까지 고려해야한다면 어떻게 알고리즘을 수정할 수 있을 까?
A* search
위와 같은 상황을 보정하기 위해서는 해당 노드의 목적지까지 거리 뿐만아니라 해당 노드에 가기까지에 든 비용을 고려할 필요가 있다.

g(n)은 해당 노드에 도착하기까지 쓴 비용을 나타내고
h(n)은 Greedy Search와 휴리스틱 함수와 같이 목적지까지의 거리를 나타낸다.
각 노드를 위의 두 함수에 입력으로 주었을 때 나오는 값이 작은 노드를 선택하는 방식을 A* Search 라고 한다.Greedy Search를 사용할 때 모든 노드의 휴리스틱 함수 값은 아래와 같았다. 여기에 g(n)을 더하여 어떻게 알고리즘이 수정되었는지 보자.
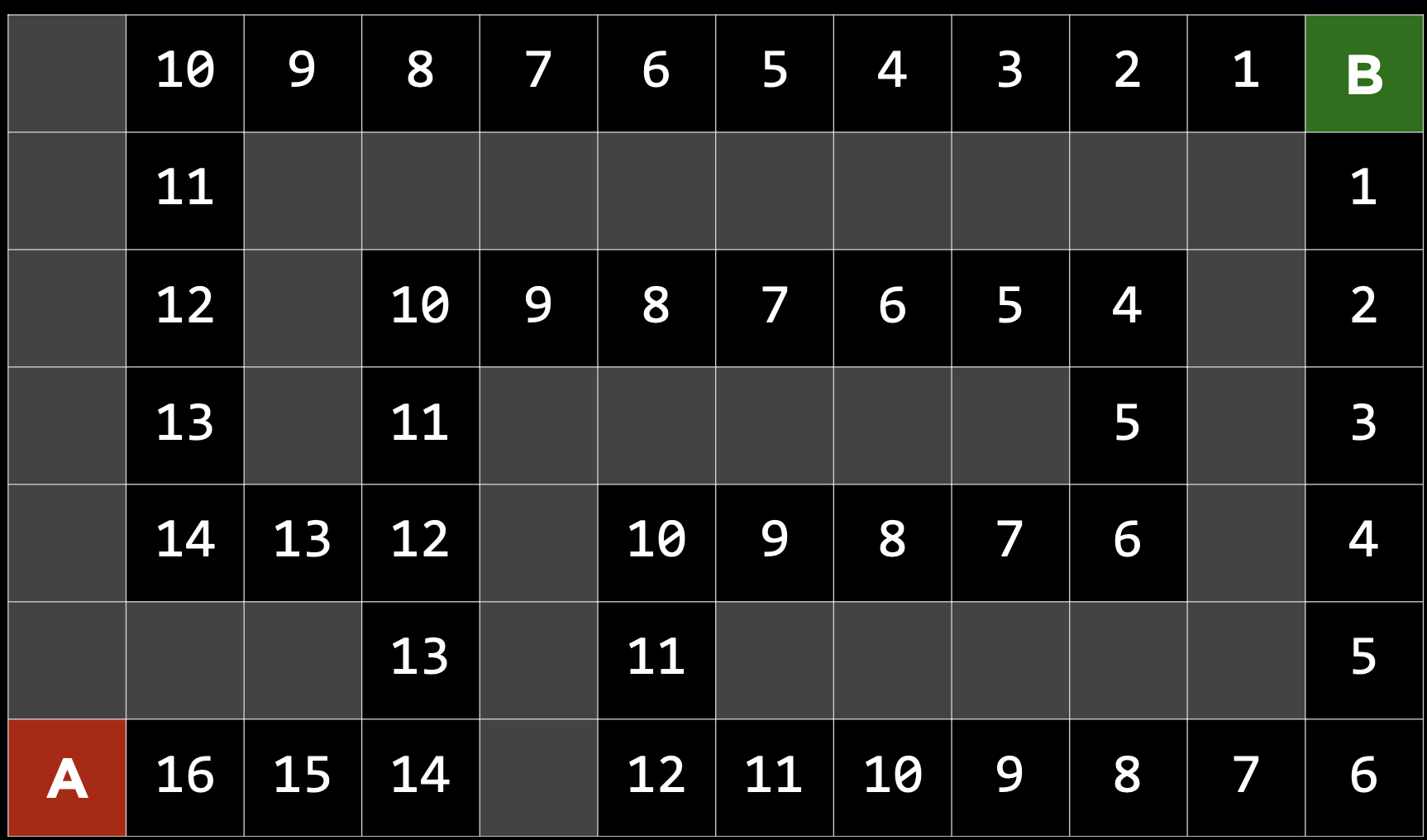
각 노드에 h(n) 값에 해당 노드까지의 비용을 더하면 다음과 같이 진행된다.
첫번째 분기점에서 g(n)을 더해도 왼쪽은 13+6 = 19 오른쪽은 11+6=17로 왼쪽보다 오른쪽이 합이 적으므로 오른쪽 경로를 선택한다.
-> 여기까지는 앞서 본 Greedy Search와 동일하다.
하지만 해당 경로를 따라 계속 들어가다보면 총 비용이 19가 되고 다음 노드의 비용은 19를 초과해서 첫번째 분기점의 19가 비용이 더 적어진다.
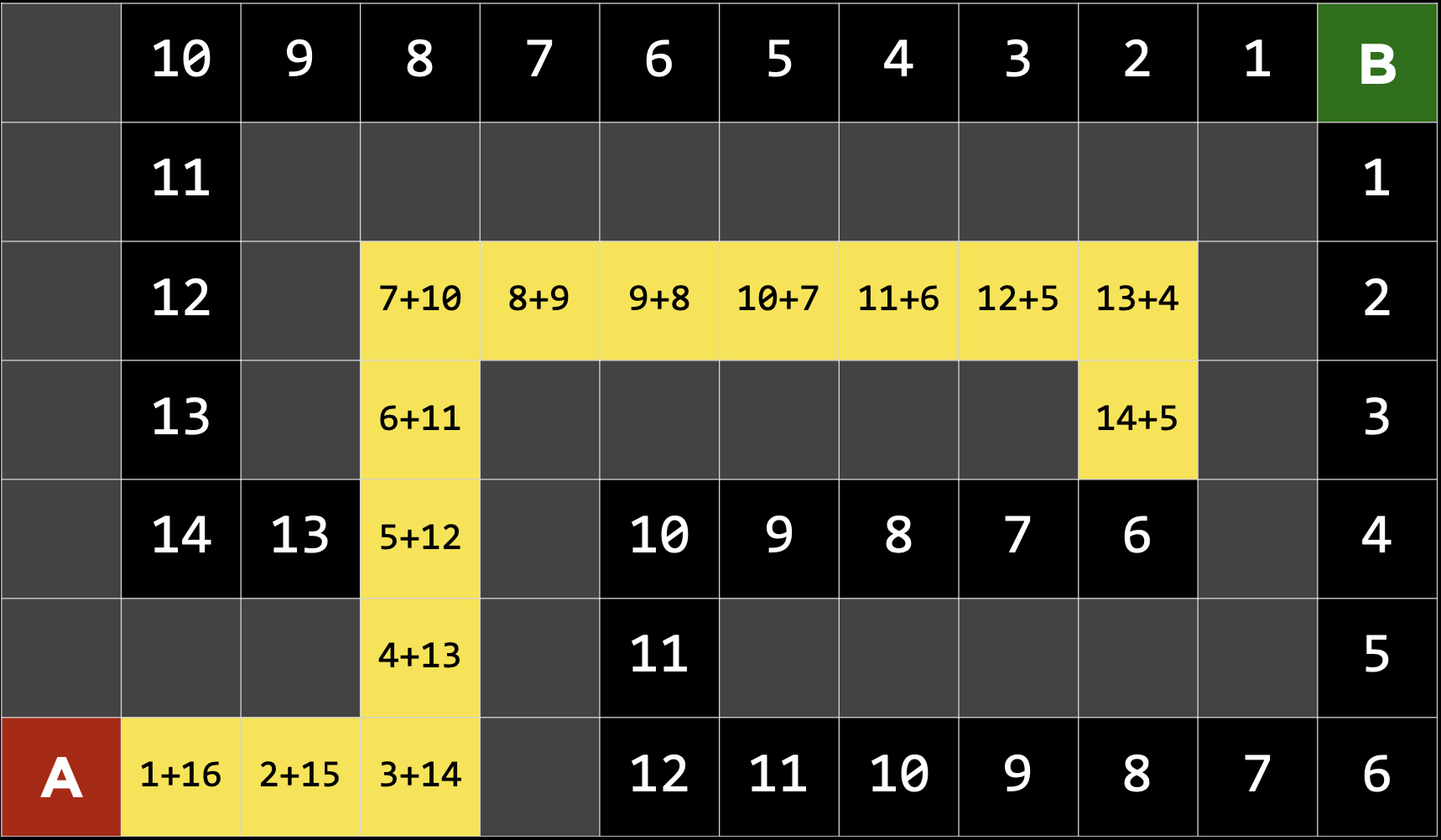
따라서 총 비용이 더적은 첫번째 분기점의 왼쪽 경로로 돌아가고 총 비용이 더 적은 노드들을 선택하여 목적지에 도달한다.

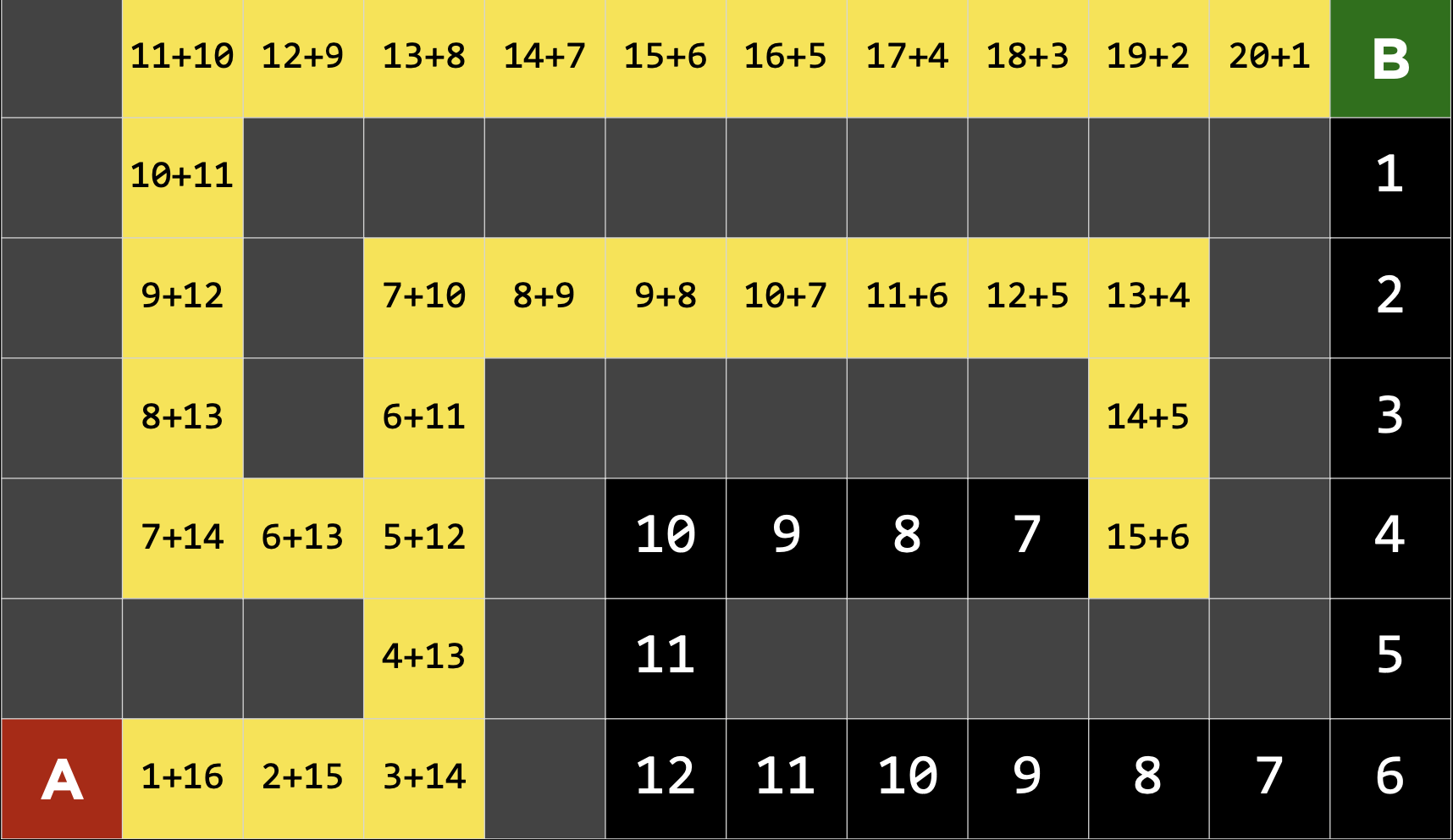
위의 예에서 알수 있듯이 A* 알고리즘은 현재노드에서 목적지까지 거리 뿐만아니라 여태까지 쓴 비용까지 고려한다. 매몰되는 비용이 너무 커지기 시작하면 이전에 선택을 번복함으로써 더 나은 솔루션을 찾을 수 있도록 한다.